主题
什么是自然语言处理 – NLP
每种动物都有自己的语言,机器也是!
自然语言处理(Natural Language Processing, NLP)是人工智能领域的核心分支,旨在让计算机理解、处理并生成人类自然语言,从而实现人机间的有效沟通。从本质上看,它是连接人类语言符号系统与机器数字处理系统的桥梁,解决了"人类语言"与"机器语言"之间的语义鸿沟问题。
人类通过语言来交流,狗通过汪汪叫来交流。机器也有自己的交流方式,那就是数字信息。
不同的语言之间是无法沟通的,比如说人类就无法听懂狗叫,甚至不同语言的人类之间都无法直接交流,需要翻译才能交流。
而计算机更是如此,为了让计算机之间互相交流,人们让所有计算机都遵守一些规则,计算机的这些规则就是计算机之间的语言。
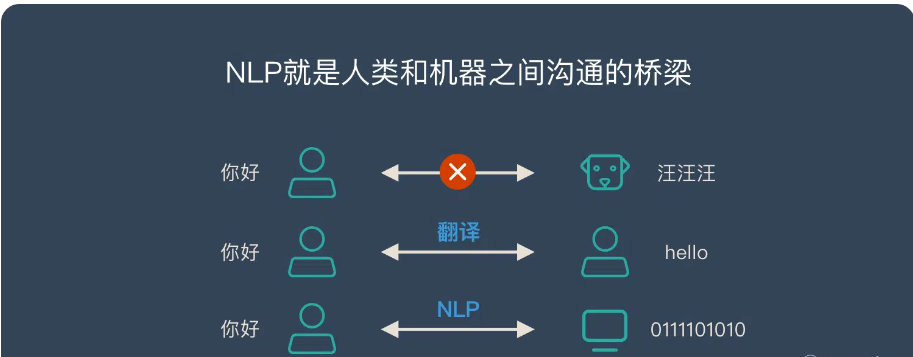
既然不同人类语言之间可以有翻译,那么人类和机器之间是否可以通过"翻译"的方式来直接交流呢?
NLP 就是人类和机器之间沟通的桥梁!
为什么是"自然语言"处理?
自然语言就是大家平时在生活中常用的表达方式,大家平时说的「讲人话」就是这个意思。
自然语言:我背有点驼(非自然语言:我的背部呈弯曲状)
自然语言:宝宝的经纪人睡了宝宝的宝宝(微博上这种段子一大把)
如上述举例,"自然语言"区别于形式化语言(如编程语言),具有以下复杂而深刻的特征:
高度的歧义性(Ambiguity):歧义是自然语言处理中最核心的挑战之一。
- 词法歧义:同一个词可能有多种含义。例如,"苹果"可以指水果,也可以指苹果公司;"意思"这个词在"你这是什么意思?"和"送你一点小意思"中的含义截然不同。
- 结构歧义:句子结构不清晰导致多种解释。例如,"研究生成绩"可以理解为"研究/生/成绩"(research/generate/grades)或者"研究生/成绩"(postgraduate's grades)。经典的英文例子是 "I saw a man with a telescope",究竟是"我用望远镜看到了一个人",还是"我看到了一个拿着望远镜的人"?
- 语义歧义:"宝宝的经纪人睡了宝宝的宝宝"这个网络段子,如果缺乏对娱乐新闻背景和网络流行语的了解,机器很难理解其中复杂的人物关系和真实含义。
对语境的强依赖性(Context-dependency):一句话的真正含义往往需要结合上下文才能确定。
- 对话历史:在对话中,"好的"这个回答可能表示同意、收到、或者敷衍,具体含义取决于前面的对话内容。
- 物理与社会环境:在暴雨天说"今天天气真好",这很可能是一句反话。机器需要具备对环境的感知和常识推理能力才能正确理解。
非标准化与多样性(Variety and Non-Standardness):与格式规整的计算机语言不同,自然语言充满了变化。
- 用词灵活:同一个意思有多种表达方式,如"我饿了"、"我肚子空了"、"我想吃点东西"。
- 语法多变:口语中常常出现不完整的句子、省略、甚至是语法错误,但人类依然可以理解。
- 新词与俚语:网络时代新词(如"YYDS"、"绝绝子")层出不穷,给机器的理解带来了持续的挑战。
承载深厚的文化与知识(Cultural and World Knowledge):语言是文化的载体。
- 成语与典故:像"画蛇添足"、"对牛弹琴"这类成语,背后都有一个故事,不了解文化背景就无法理解其比喻义。
- 常识知识:理解"他游过了河"这句话,需要一个常识:人和河是两个物体,河里是水,人可以通过游泳的方式从河的一侧到另一侧。这些对人类不言而喻的知识,机器却需要通过大量的学习才能掌握。
NLP的两大核心任务
NLP主要包含两个核心任务:自然语言理解(NLU)和自然语言生成(NLG)。
自然语言理解(NLU/NLI)

自然语言理解旨在让机器具备人类级别的语言理解能力。这个任务面临着多重挑战:
- 语言的多样性:不同语言、方言、俚语的表达方式差异巨大,如汉语的"你吃了吗"在英语中需根据场景译为"Have you eaten?"或"How are you?"。
- 语言的歧义性:词语或句子可能有多重含义,需要通过上下文和背景知识来消除歧义。
- 语言的鲁棒性:需要处理拼写错误、口语化表达等非标准用语。
- 语言的知识依赖:理解语言往往需要丰富的世界知识和常识推理能力。
- 语言的上下文关联:单句含义需结合具体语境来判断。
自然语言生成(NLG)

自然语言生成是将非语言数据(如图表、结构化信息)转化为人类可理解的自然语言文本。其实现过程包含以下核心步骤:
- 内容确定:筛选需要表达的关键信息
- 文本结构:规划文本的整体框架
- 句子聚合:将分散信息整合为连贯句子
- 语法化:选择合适的词汇和语法结构
- 参考表达式生成:处理指代关系
- 语言实现:生成最终的自然语句
NLP的技术途径
NLP有两种主要的技术实现途径:传统机器学习方法和深度学习方法。
传统机器学习途径

主要特点:
- 语料预处理:清洗数据、分词、特征提取(如词频TF-IDF)
- 特征工程:手动设计特征,选择合适的分类器
- 优势:可解释性强,适合小规模数据
- 局限:特征设计依赖专家经验,泛化能力有限
深度学习途径

主要特点:
- 语料预处理:更依赖分布式表示(如词向量)
- 模型设计:使用神经网络自动学习特征
- 优势:端到端训练,适用于大规模数据
- 局限:可解释性较弱,需要大量训练数据
NLP的典型应用
1. 情感分析
- 核心目标:从文本中提取情感倾向
- 应用场景:产品评价分析、舆情监控、用户反馈分析
- 技术实现:基于词袋模型或深度学习模型识别情感倾向
2. 智能对话系统
- 发展阶段:从规则式到智能对话
- 关键技术:意图识别、对话管理、回复生成
- 应用场景:智能客服、智能助手、心理咨询
3. 语音识别(ASR)
- 技术流程:声音信号→文本转换
- 典型应用:语音输入、实时字幕、语音导航
- 技术挑战:噪音处理、方言识别、口语理解
4. 机器翻译
- 技术演进:规则→统计→神经网络
- 应用工具:Google翻译、DeepL等
- 现状挑战:专业领域准确性、文化内容翻译
NLP的未来发展趋势
- 大规模预训练模型:如GPT、BERT等模型的持续进化
- 多模态融合:结合文本、图像、语音的综合处理
- 领域深化:在医疗、法律、教育等专业领域的深度应用
- 知识增强:融入更多世界知识和常识推理能力
- 低资源语言:扩展对小语种的支持
总结
自然语言处理(NLP)作为人工智能的重要分支,正在快速发展并改变着我们的生活方式。它通过"理解"与"生成"两大核心任务,构建了人机交互的语言桥梁。虽然当前NLP技术已经取得了显著进展,但在处理语言的歧义性、文化内涵等方面仍面临挑战。未来,随着技术的不断进步,NLP将在更多领域发挥重要作用,推动人机交互迈向新的高度。